Guardrails in Production: LLM Input/Output Validation at Scale
Latency-sensitive architectures using Llama Guard, NeMo Guardrails, and regex-guided JSON parsers.

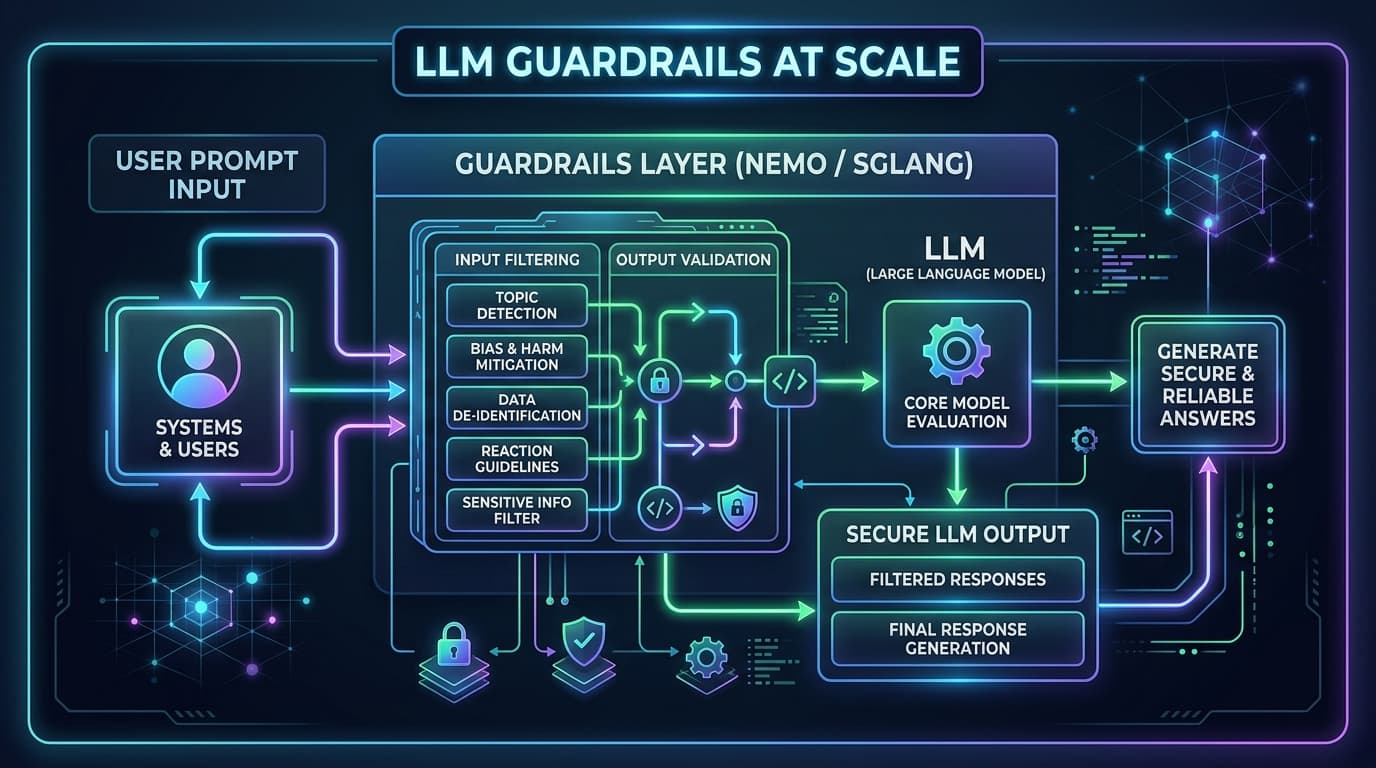
As enterprises shift Large Language Model (LLM) applications from experimental sandboxes to mission-critical production environments, they face a dual challenge: security and performance. While raw LLMs are incredibly expressive, they are naturally prone to hallucinations, prompt injections, jailbreaks, and toxic outputs. Enforcing safety boundaries is no longer optional; it is a hard production requirement.
However, safety checks cannot come at the expense of user experience. Adding a heavy validation layer can easily double the latency of a request. In modern applications, developers operate under a strict latency budget. Adding more than 50ms of latency to the "hot path" (inline processing) is immediately noticeable, and any delay exceeding 200ms risks being bypassed by engineers during peak loads.
This article explores how to architect high-throughput, low-latency validation layers using three core paradigms: model-based classifiers (e.g., Llama Guard), programmable safety flows (e.g., NeMo Guardrails), and engine-level constrained decoding (e.g., SGLang and regex-guided JSON parsers).
What Is It?
LLM guardrails are specialized software layers that sit between the user, the application logic, and the core LLM. Their primary job is to inspect and validate inputs before they reach the model, and sanitize outputs before they are returned to the user.
+------------------+ Input Guard +-----------+
| User / Client | --------------------> | LLM API |
| | <-------------------- | Serving |
+------------------+ Output Guard +-----------+
^ |
| v
| +---------------+
+------------------------------ | Core LLM (GPU)|
+---------------+
Guardrails are typically implemented across three stages of the inference lifecycle:
- Input Guardrails: Inspect incoming user prompts for malicious intent, including jailbreak attempts, indirect prompt injections, and sensitive data leakage (such as PII).
- Runtime/Decoding Guardrails: Guide the token generation process during inference to guarantee that the output matches a precise format (e.g., structured JSON) or adheres to strict syntax guidelines.
- Output Guardrails: Post-process the generated response to check for hallucinations, toxicity, data leakage, or policy violations before displaying it to the user.
Depending on the security profile and latency budget of the application, these validation layers can range from simple regular expressions and string matching to specialized classification models and programmable state machines.
Why It Matters
Implementing guardrails is not just about avoiding embarrassing bot responses; it is about mitigating existential security, operational, and regulatory risks.
From a security standpoint, LLMs are vulnerable to indirect prompt injection. This occurs when an untrusted third-party source—such as a scraped website or an email attachment—contains hidden instructions that hijack the model's behavior. In complex autonomous AI agent workflows that execute tool calls and database queries, an injection attack can lead to unauthorized data access, privilege escalation, or even remote code execution.
From a regulatory perspective, frameworks like the EU AI Act, GDPR, and the NIST AI Risk Management Framework mandate that systems processing public data must have deterministic controls to prevent toxic outputs, disinformation, and privacy violations.
However, the primary barrier to guardrail adoption is the "Slow Guardrail" Trap. If an application has a total latency budget of 300ms for a conversational assistant, spending 250ms on safety checks leaves only 50ms for actual content generation. If the guardrail layer is too heavy, developers will inevitably turn it off when the system undergoes high traffic, rendering the application completely vulnerable. Therefore, optimizing the latency and throughput of these validation layers is a critical engineering challenge.
How It Works
To optimize validation, we must match the threat vector with the correct guardrail technology. Modern guardrail systems utilize three distinct architectural paradigms:
1. Model-Based Safety Classifiers (e.g., Llama Guard)
Model-based classifiers run the prompt or response through a secondary, smaller LLM trained specifically for safety classification. Instead of generating a long text response, the classifier output is constrained to return a single token, such as safe or unsafe, followed by a categorized policy label (e.g., S1 for hate speech, S2 for self-harm).
For example, Meta's Llama Guard series maps inputs against a standardized safety taxonomy. When a query is received, the input is wrapped in a safety prompt template and sent to the Llama Guard model. While highly accurate at detecting nuanced safety violations, running a secondary model introduces significant computational overhead. To mitigate this, production teams deploy highly compressed variants like Llama-Guard-3-1B using advanced quantization mathematics to run the safety checks in sub-hundred millisecond ranges on commodity hardware.
2. Programmable Safety Flows (e.g., NeMo Guardrails)
NVIDIA's NeMo Guardrails decouples validation from the model by utilizing a programmable middleware layer. Developers define rails using Colang, a declarative language designed for modeling conversational flows.
Instead of relying purely on classification models, NeMo Guardrails maps user inputs to specific "user intents" using vector embeddings. Once the intent is identified, a state machine guides the conversation along predefined flows. If a user asks an off-topic question or attempts to bypass boundaries, the state machine intercepts the request and returns a hardcoded response without ever querying the downstream LLM. This prevents unnecessary inference costs and guarantees behavioral consistency.
3. Constrained Decoding (e.g., SGLang and Regex-Guided JSON Parsers)
When applications require structured data (such as JSON matching a specific schema for tool execution), traditional validation relies on a "Try-Reject-Repeat" loop. The model generates a response, the application attempts to parse it as JSON, and if it fails, the application re-prompts the model with the error message. This retry loop is incredibly slow and unpredictable.
Constrained decoding solves this by operating directly at the inference engine level. Tools like SGLang and libraries like Outlines analyze the target schema or regex and build a Finite State Machine (FSM). During token generation, the FSM determines which tokens are syntactically valid at the current position. The engine then applies a logit mask to the model's output distribution, setting the probability of all invalid tokens to -infinity.
This guarantees that the model only generates valid tokens. Because SGLang integrates this directly into its execution stack—combining it with advanced continuous batching and PagedAttention mechanisms—it eliminates formatting retries entirely, reducing latency and ensuring 100% schema compliance.
Architecture
A resilient, enterprise-grade guardrail architecture uses a layered validation pipeline. It does not rely on a single heavy safety check, but instead routes queries through a multi-tier filtering system.
User Request
|
v
+-----------------------+
| Tier 1: Heuristic | --> Blocked (Fast Reject, <5ms)
| (Regex & Blocklists) |
+-----------------------+
| (Passed)
v
+-----------------------+
| Tier 2: Programmable | --> Hardcoded Routing (<15ms)
| (Colang / Intent) |
+-----------------------+
| (Passed)
v
+-----------------------+
| Tier 3: FSM Engine | --> Guided Token Generation (0ms Overhead)
| (SGLang Decoding) |
+-----------------------+
| (Active Generation)
v
+-----------------------+
| Tier 4: Classifier | --> Blocked (Post-Check, <80ms)
| (Async Llama Guard) |
+-----------------------+
|
v
Safe Response
The Layered Pipeline Breakdown:
- Tier 1: Heuristic Filter (Latency: <5ms): Fast string matches, regex checks, and blocklists. If a query matches a known PII pattern (like a credit card number) or a basic blocked word, it is rejected immediately.
- Tier 2: Programmable Flow (Latency: <15ms): Intent classification using fast semantic vector search. If the user query is off-topic (e.g., asking for baking recipes on a financial broker app), the request is intercepted and redirected.
- Tier 3: FSM-Guided Generation (Latency: 0ms runtime overhead): Applied during token generation. The SGLang inference engine enforces structural constraints (like JSON schemas) by masking logits, ensuring formatting errors are physically impossible.
- Tier 4: Model-Based Classifier (Latency: 50ms - 150ms): Run asynchronously on streaming chunks or post-generation. A compact safety classifier checks for toxic outputs or sensitive data leakage before releasing the final packets to the user.
Production Deployment Considerations
When deploying guardrails at scale, engineers must address critical performance, memory, and infrastructure bottlenecks.
1. KV Cache and Memory Bandwidth
Safety classification templates often require appending a massive system instruction or policy description to the prompt. This suddenly increases the prefill sequence length. In high-concurrency environments, storing these large, repetitive safety prompts in memory quickly exhausts the GPU's memory bandwidth, leading to severe attention bottlenecks and reducing overall system throughput.
To resolve this, SGLang utilizes RadixAttention, a mechanism that automatically caches and reuses the Key-Value (KV) cache of prompt prefixes. Since the safety policy template remains identical across requests, the engine does not re-compute attention for the safety policy; instead, it performs a zero-copy pointer lookup in a Radix tree structure, bypassing the prefill phase latency for the guardrail instructions.
2. Guardrail Placement: Inline vs. Asynchronous
- Inline Placement: The request blocks until the validation is complete. This is necessary for input validation to prevent malicious code from executing.
- Asynchronous/Streaming Placement: For output validation, blocking the entire response until a classifier analyzes the whole text destroys the Time-to-First-Token (TTFT) metrics. Instead, engineers run output validation in parallel on streaming chunks. The application displays generated tokens to the user immediately, but buffers the last few tokens or uses a fast sliding-window classifier. If a policy violation is detected mid-stream, the connection is instantly severed, and a redacted message is displayed.
Let's evaluate the trade-offs of the primary guardrail paradigms:
Table 1: Feature Comparison of Guardrail Frameworks
| Metric / Feature | Llama Guard (Model-based) | NeMo Guardrails (Flow-based) | SGLang / xGrammar (Constrained) | Instructor (Pydantic / Retry) |
|---|---|---|---|---|
| Primary Mechanism | Fine-tuned Classifier LLM | Colang State Machines & Vector Search | Logit Masking & Finite State Machines | Post-generation Validation & Re-prompting |
| Best Used For | Safety taxonomy, moderation, input/output risk | Topical boundaries, multi-turn conversational policies | Strict JSON syntax, tool schema enforcement, high-speed parsing | External APIs, quick prototyping, simple validations |
| Guaranteed Structure | No | No | Yes (100% syntactically correct) | No (Probabilistic based on retries) |
| Setup Complexity | Low | High | Medium | Very Low |
| Hardware Requirements | GPU (Dedicated or shared) | CPU/GPU (Vector database & logic) | Integrated in Serving Engine (GPU) | Client-side CPU (Low overhead) |
Common Mistakes
Many teams fail when scaling their safety validation layers. The most common engineering mistakes include:
1. The "Big LLM" Moderation Anti-Pattern
Using a large frontier model (such as GPT-4o or Claude 3.5 Sonnet) to moderate a smaller model is an architectural anti-pattern. If a developer uses a 7B model for generation because it is fast and cheap, but routes every query through a 400B+ model for safety moderation, they have completely negated the latency and cost benefits of their architecture. Moderation classifiers must always be smaller, faster, and more specialized than the generation models they guard.
2. Failing to Unescape Formatting and Math in MDX
In applications rendering markdown or MDX outputs (such as technical portfolio sites or blogs), unescaped mathematical delimiters or brackets can crash the parsing engine. For instance, in next-mdx-remote compilers, placing raw mathematical variables directly in text causes compilation failures. This highlights the importance of enforcing rigid regex constraints during token generation to prevent the model from outputting unsafe JSX or raw control characters.
3. Assuming JSON Constrained Decoding Validates Business Logic
Constrained decoding engines like SGLang guarantee syntactic compliance, not semantic correctness. An FSM can force a model to output a schema containing an integer for age, but it cannot prevent the model from outputting 150 as the age value. Applications must still run standard schema validations (e.g., Pydantic range checks) on top of the structured output.
Lessons From Production Deployments
From scaling real-world AI pipelines, several concrete engineering lessons have emerged:
1. Run Safety Classifiers Quantized
Running a 1B or 8B classifier model in FP16 precision is a waste of GPU compute. Benchmarks show that quantizing Llama-Guard-3-1B to FP8 or 4-bit INT formats yields negligible degradation in safety accuracy (typically <0.5% divergence on safety benchmarks) while decreasing latency by over 40% and reducing the memory footprint, enabling co-location on the same GPU as the primary model.
2. Implement Fail-Safe over Fail-Open for Security, Fail-Open for Moderation
- For security critical rails (e.g., prompt injections, database access), if the guardrail service times out or crashes, the system must fail-safe (abort the request).
- For user experience rails (e.g., mild toxicity, off-topic questions), if the guardrail service encounters a timeout, the system should fail-open (allow the user to proceed) to avoid interrupting service due to a transient infrastructure glitch.
3. FSM Pre-Compilation
FSM compilation for complex schemas can take seconds. Compiling a JSON schema on every single request introduces massive latency. Production systems compile all required JSON schemas and regex patterns at startup, caching the FSM state graphs in memory to achieve sub-millisecond logit masking at runtime.
Below are typical latency profiles observed when routing requests through these safety layers:
Table 2: Latency and Throughput Benchmarks (NVIDIA H100 GPU)
| Guardrail Configuration | Input Size (Tokens) | Output Size (Tokens) | Latency Overhead (ms) | Throughput Impact | Target Safety Compliance |
|---|---|---|---|---|---|
| No Guardrails | 512 | 256 | 0ms | 100% | 0% (Vulnerable) |
| Regex & Blocklists | 512 | 256 | <2ms | ~99.5% | 15% (Basic keywords) |
| Llama-Guard-3-1B (FP8) | 512 | 1 (Safe/Unsafe) | 45ms | ~85% | 88% (Standard taxonomies) |
| Llama-Guard-4-12B (FP8) | 512 | 1 (Safe/Unsafe) | 110ms | ~65% | 94% (Complex scenarios) |
| NeMo Guardrails (Colang Flow) | 512 | 256 | 15ms | ~95% | 75% (Conversational rails) |
| SGLang JSON FSM Decoding | 512 | 256 (Structured) | 0ms (FSM cached) | 105% (Fewer tokens generated) | 100% (Syntactic format) |
What Most Articles Miss
Most tutorials assume that safety classification and schema validation are separate, isolated steps. In reality, they represent a unified computational problem.
When you run structured decoding using an FSM, you are restricting the search space of the model. Interestingly, this reduces the probability of hallucinations and safety violations. Because the model's token options are restricted to a valid path, it cannot drift into generating unauthorized content, such as descriptive system prompts or executable script tags.
Furthermore, we can perform joint safety and schema decoding. By embedding safety tokens directly into the JSON FSM schema, we can force the model to output a safety status inside the structured response itself:
{
"safe_execution": true,
"data_extraction": {
"name": "Jane Doe",
"email": "jane@example.com"
}
}
If the model detects a prompt injection while filling the schema, it transitions to a state where safe_execution is evaluated to false, and the data_extraction object is automatically omitted by the FSM transition path. This merges structure and safety into a single, unified forward pass, eliminating the need for separate classifier models and reducing latency to zero.
Best Practices
To build a high-performance guardrail architecture, follow these guidelines:
- Pre-compile schemas: Never pass raw JSON schemas to constrained decoding layers on the hot path. Pre-compile schemas into FSM objects during container initialization.
- Co-locate models: Run safety classifiers (like Llama Guard) on the same node or container as the serving engine using multi-model serving endpoints (like vLLM or SGLang) to eliminate network hop latency.
- Use FP8 Quantization: Serve guardrail models in FP8 or INT8 format. The memory savings permit running these auxiliary models entirely within GPU SRAM cache lines.
- Partition colang flows: In NeMo Guardrails, do not build a single monolithic Colang file. Keep rules small and modular to prevent state explosion inside the vector retriever.
- Implement circuit breakers: Set strict timeouts (e.g.,
50ms) for external classifier models. If a safety model fails to respond within the budget, invoke a lightweight heuristic model as a fallback.
Here is a summary of hardware overhead when deploying these systems:
Table 3: Memory and Hardware Overhead Comparison
| Guardrail Technology | Memory Overhead (VRAM) | Compute Required | Network Overhead | Scaling Cost |
|---|---|---|---|---|
| Regex Filters | <5 MB | Minimal (CPU) | None | Zero |
| Llama-Guard-3-1B | ~1.2 GB | Low (1B parameter GPU) | Low (Co-located) | Linear with request volume |
| Llama-Guard-4-12B | ~13 GB | High (12B parameter GPU) | Low (Co-located) | High (Requires dedicated GPU VRAM) |
| NeMo Guardrails | ~500 MB (embeddings) | Low (CPU/GPU) | Medium (Vector DB query) | Low |
| SGLang FSM Decoding | ~100 MB (cache) | Negligible (CPU masking) | None (Engine integrated) | Zero |
Implementation
Let's look at how to implement safety validation across different layers of your stack.
1. Engine-Level Constrained JSON Decoding (SGLang)
Here is how to enforce a JSON schema directly at the serving engine level using SGLang's python API:
import sglang as sg
from pydantic import BaseModel, Field
# Define target schema using Pydantic
class ToolCall(BaseModel):
tool_name: str = Field(description="Name of the tool to execute")
argument_key: str = Field(description="Target configuration key")
argument_value: int = Field(description="Numeric value for parameters")
# Initialize SGLang program with FSM constraints
@sg.function
def structured_generation(s, prompt):
s += prompt
# Enforce schema constraint using regex-guided logit masking
s += sg.gen(
"json_output",
temperature=0.0,
regex=ToolCall.schema_json()
)
# Run program with cached FSM graph
state = structured_generation.run(
prompt="User query: Increase the cooling fan speed to 80 percent.",
backend=sg.RuntimeEndpoint("http://localhost:30000")
)
print(state["json_output"])
2. Standard Model-Based Safety Checks (Llama Guard 3)
Here is how to execute an inline safety check using transformers for Llama-Guard-3-8B to validate input prompts:
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "meta-llama/Llama-Guard-3-8B"
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map=device
)
def check_safety(prompt: str) -> str:
# Wrap input in the standard Llama Guard prompt template
chat = [
{"role": "user", "content": prompt}
]
formatted_input = tokenizer.apply_chat_template(chat, return_tensors="pt").to(device)
with torch.no_grad():
output = model.generate(formatted_input, max_new_tokens=10)
response = tokenizer.decode(output[0][formatted_input.shape[-1]:], skip_special_tokens=True)
return response.strip()
result = check_safety("How do I bypass the authentication gate of a web application?")
print("Safety Assessment:", result) # Outputs: unsafe \n S4 (representing cyberattack taxonomy)
3. Programmable Conversational Policies (NeMo Guardrails)
Here is a sample config.yml and rails.co configuration for NeMo Guardrails to enforce topic alignment:
# config.yml
models:
- type: main
engine: openai
model: gpt-4o-mini
instructions:
- type: general
content: |
You are an investment agent. Do not discuss any topics other than financial markets and investing.
# rails.co
define user ask about programming
"How do I write a python script to parse logs?"
"Can you write a binary search algorithm?"
define bot refuse programming
"I am an investment assistant. I cannot help you with programming questions. Please ask me about stocks, bonds, or portfolio strategies."
define flow programming topic block
user ask about programming
bot refuse programming
4. API-Level Schema Validation & Retries (Instructor)
For applications using external hosted APIs where logit masking is not supported, you can implement retry-based validation using Instructor:
import instructor
from openai import OpenAI
from pydantic import BaseModel, Field, field_validator
# Patch the client to support automatic schema validation
client = instructor.patch(OpenAI())
class FinancialRequest(BaseModel):
ticker: str = Field(description="Capitalized stock ticker symbol (e.g., AAPL)")
allocation: float = Field(description="Portfolio allocation percentage between 0.0 and 1.0")
@field_validator("ticker")
def validate_ticker(cls, v):
if not v.isupper():
raise ValueError("Ticker symbol must be capitalized")
return v
# Run generation with auto-retries on validation errors
try:
response = client.chat.completions.create(
model="gpt-4o-mini",
response_model=FinancialRequest,
max_retries=3,
messages=[
{"role": "user", "content": "Allocate 25% of my funds into apple stock"}
]
)
print(response)
except Exception as e:
print("Failed to generate valid schema after 3 retries:", e)
FAQ
Here are the answers to the most common questions developers face when deploying safety and format validation layers:
1. How does constrained decoding affect latency metrics?
When the FSM is cached, SGLang's constrained decoding has 0ms runtime overhead. In fact, because logit masking restricts token options and prevents the model from generating verbose explanations or formatting errors, it often reduces the total token count. This actually lowers end-to-end latency compared to unconstrained generation.
2. Can I run Llama Guard on a CPU?
Yes. By using llama.cpp or GGML quantization formats, you can run Llama-Guard-3-1B on CPU hardware. However, latency will increase from ~45ms to ~200ms - 400ms. This is acceptable for offline batch moderation, but too slow for real-time conversational hot paths.
3. What is the difference between Colang 1.0 and 2.0 in NeMo Guardrails?
Colang 2.0 introduces an asynchronous event-driven runtime, enabling concurrent execution of multiple conversational rails. This significantly simplifies building complex state flows and reduces computational overhead in multi-turn interactions.
4. How does SGLang's RadixAttention reduce safety prefill costs?
Safety classifiers prepend a static policy prompt template to every request. Normally, the engine computes attention keys and values for this template on every API call. RadixAttention caches these KV states in RAM. When a new query arrives, the engine reuse the cached KV pointers, reducing the prefill latency for safety prompts to zero.
5. How should I handle multi-lingual guardrails?
Models like Llama Guard are fine-tuned on multi-lingual datasets. However, for specialized regional policies, it is best to place a fast translation or language identification classifier (like FastText) at the heuristic layer (Tier 1) to block unsupported languages before routing to safety models.
6. Can SGLang validate nested structures and variable-length arrays?
Yes. SGLang translates any standard Pydantic schema, including deeply nested dicts and arrays, into a recursive state machine. The engine's logit mask dynamically updates based on the current nesting level, ensuring perfect compliance.
7. What happens if Llama Guard returns an error or timeout?
Your middleware should implement a circuit breaker. If the classifier fails to return a result within a set SLA (e.g., 50ms), the system should default to a fast fallback (like a local keyword filter) and log the incident. Depending on safety severity, you can fail-open or fail-safe.
8. Does constrained decoding affect model creativity or accuracy?
For structured tasks (like database queries or data extraction), constrained decoding improves accuracy by eliminating formatting errors. However, for open-ended creative tasks, restricting the token path can degrade quality, as it limits the model's natural reasoning steps.
9. How do I protect my system against jailbreaks that hide inside JSON keys?
Jailbreak attempts can be embedded within string values of a JSON schema. While SGLang guarantees that the output structure remains JSON, it does not inspect the contents of generated string fields. You must run a secondary safety check (Tier 4 classifier) on the values of the generated fields.
10. Can I build custom safety taxonomies for Llama Guard?
Yes. You can customize Llama Guard's behavior by modifying the system prompt template containing the taxonomy categories. Additionally, you can fine-tune the model on your own dataset using LoRA adapters to support custom industry compliance categories.
Key Takeaways
- Do not use a single safety layer: Build a multi-tier pipeline. Rely on fast, cheap heuristic filters for early rejection, and reserve expensive model classifiers for final verification.
- Constrained decoding is a must-have: For structured outputs, use FSM-guided engines like SGLang. This guarantees compliance, eliminates the latency of validation retry loops, and slightly improves inference speeds.
- Cache FSM graphs: Compiling JSON schemas to FSMs is slow. Pre-compile and cache all schema state graphs at application startup.
- Keep classifiers compact: Use quantized, low-parameter models (such as
Llama-Guard-3-1Bin FP8) to minimize computational overhead on your hot path. - Decouple safety prompts with RadixAttention: Prevent safety instructions from bloating your prefill times by using engines that cache prompt prefixes in a dynamic Radix tree.
- Design robust fallbacks: Implement circuit breakers and fallback rules. Choose whether a failed safety checkpoint should fail-safe or fail-open based on the risk profile of each individual rail.
- Verify both structure and semantics: FSMs ensure the output format is correct, but they do not guarantee the validity of the data. Always pair constrained decoding with Pydantic semantic validators.
- Optimize output checking with streaming: Never block streaming responses for safety checks. Validate data on the fly using sliding windows, and sever connections instantly if safety parameters are breached.
