Designing High-Throughput Inference Engines: Continuous Batching vs PagedAttention
How vLLM and Hugging Face TGI eliminate memory fragmentation to maximize GPU concurrency.

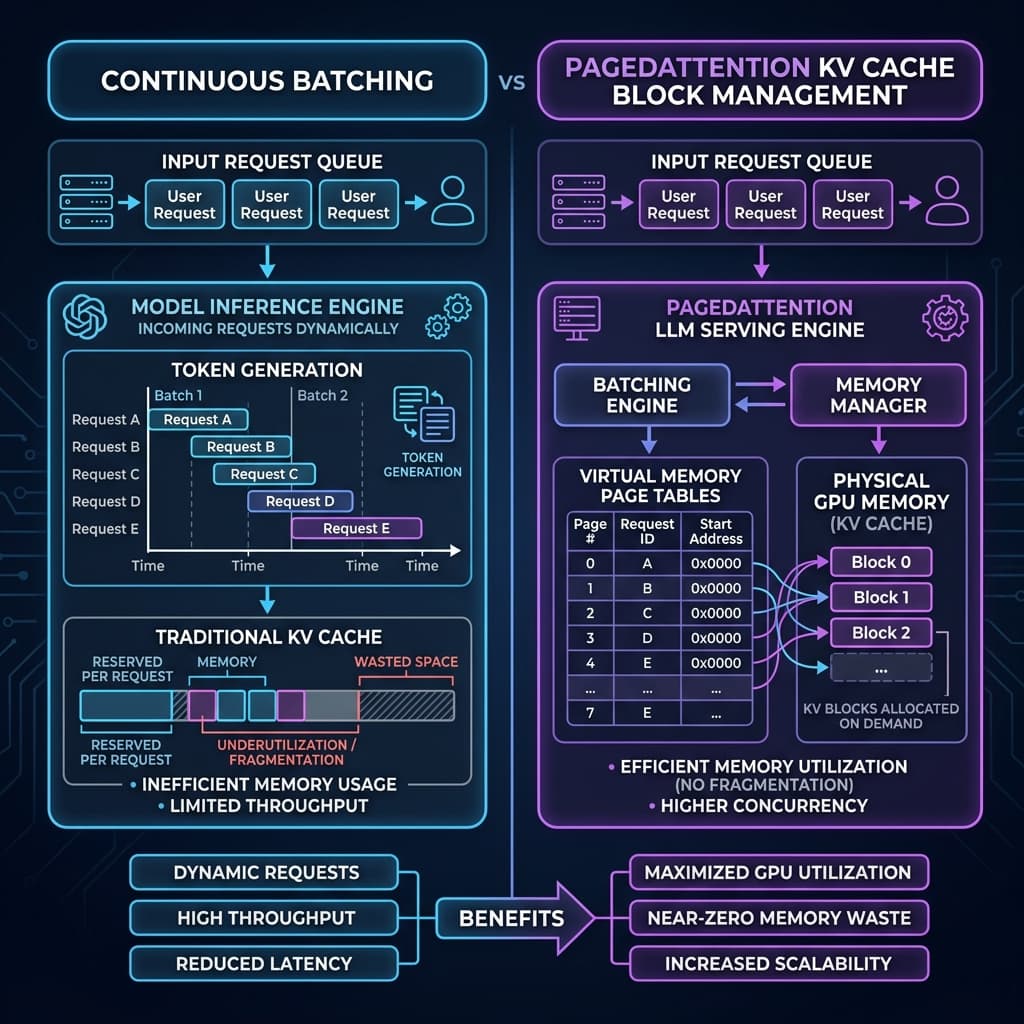
In the commercial deployment of large language models (LLMs), the transition from model training to inference serving marks a fundamental shift in engineering priorities. During training, workloads are highly compute-bound, dominated by massive, predictable matrix multiplications that keep GPU Tensor Cores fully saturated. In contrast, LLM inference serving—particularly during the token generation phase—is notoriously memory-bound, constrained by the throughput of High Bandwidth Memory (HBM) rather than raw FLOPS.
As explored in our deep dive on Mitigating Attention Bottlenecks, the autoregressive nature of LLM generation requires the system to process text one token at a time. For every generated token, the model must access the Key and Value vectors of all previous tokens. Storing these vectors—collectively known as the Key-Value (KV) cache—avoids redundant computation but introduces a massive, dynamic memory overhead. In early serving systems, this overhead led to severe memory fragmentation, limiting the batch sizes that GPUs could process and causing costs to skyrocket.
To solve the memory and scheduling bottlenecks of LLM serving, two foundational innovations emerged: Continuous Batching and PagedAttention. These techniques form the bedrock of modern inference engines like vLLM, Hugging Face Text Generation Inference (TGI), and SGLang.
This guide provides an exhaustive architectural exploration of Continuous Batching and PagedAttention, comparing how modern inference engines implement them, examining performance benchmarks, and providing concrete deployment configurations for production environments.
🧱 What Is It?
To appreciate these technologies, we must contrast them with traditional, static methods of request processing.
The Static Batching Problem
In standard web serving, batching combines multiple independent inputs into a single pass to maximize GPU compute utilization. However, LLMs present a unique challenge: the input prompts (prefill phase) and the generated outputs (decode phase) vary significantly in length.
If we use static batching, the engine groups a set of requests and runs them together. Because the engine must wait for the longest request in the batch to complete before releasing the resources, shorter requests are held hostage. The GPU cores sit underutilized during the final iterations of the batch, waiting for a single long request to finish. This is known as the "straggler problem" or the "last-token bottleneck."
Continuous Batching
Continuous Batching (also called iteration-level scheduling), first introduced in the Orca paper (Orca: A Distributed Serving System for Transformer-Based Generative Models, OSDI 2022), solves this scheduler-side inefficiency. Instead of operating on a request-level batch boundary, continuous batching operates at the iteration (token-generation) level.
The engine schedules execution dynamically after every single token generation step. When a request in the active batch finishes generating its terminal token (such as the end-of-sequence token), it is immediately evicted from the batch. A new request from the waiting queue is then inserted into the active batch, beginning its prefill phase in parallel with the ongoing decode phases of the other requests. This keeps the GPU continuously saturated, reducing queue wait times and maximizing throughput.
Static Batching:
Batch 1: [Req A: 4 tokens] ========> Done
[Req B: 8 tokens] ========================> Done (Req A waited here)
(Next batch cannot start until all requests in Batch 1 finish)
Continuous Batching:
Step 1: [Req A: token 1] [Req B: token 1]
Step 2: [Req A: token 2] [Req B: token 2]
Step 3: [Req A: token 3] [Req B: token 3]
Step 4: [Req A: Finished!] [Req B: token 4] -> [Req C (New): Prefill]
Step 5: [Req C: token 1] [Req B: token 5]
PagedAttention
While continuous batching addresses scheduling inefficiency, it does not solve the memory allocation problem. In early inference engines, the KV cache for a request had to be allocated as a single, contiguous block of VRAM. Because the total length of a request's output is impossible to predict beforehand, systems pre-allocated memory based on the model's maximum context length (e.g., 2048 or 4096 tokens).
This resulted in massive memory waste, as most requests completed long before reaching the maximum limit.
PagedAttention, introduced in the vLLM paper (Efficient Memory Management for Large Language Model Serving with PagedAttention, SOSP 2023), solves this memory-bound bottleneck by treating GPU memory in a similar way to virtual memory in operating systems.
Instead of allocating contiguous blocks of physical memory, PagedAttention partitions the KV cache of each sequence into fixed-size blocks (typically representing 16 or 32 tokens). These blocks do not need to be contiguous in physical VRAM.
The engine maintains a page table that maps the logical blocks of a request's sequence to physical blocks in GPU memory. During attention computation, a custom CUDA kernel reads these physical blocks on the fly based on the page table mappings, completely eliminating the need for contiguous layout allocation.
⚡ Why It Matters
The necessity of PagedAttention becomes clear when analyzing the physics of GPU memory allocation during autoregressive decoding.
The Compute vs. Memory Bound Paradigm
In GPU computation, kernels are classified by their arithmetic intensity, which is the ratio of mathematical operations (FLOPs) to memory accesses (bytes read/written from High Bandwidth Memory).
During the Prefill phase, the GPU processes the entire user prompt at once. This involves large matrix-matrix multiplications (GEMM), which have high arithmetic intensity. The GPU's Tensor Cores are fully utilized, making the prefill phase compute-bound.
During the Decode phase, the GPU generates tokens one by one. For each token, the GPU must load all model weights plus the entire historical KV cache from VRAM into local SRAM to calculate the attention scores. Because the number of operations per byte of memory loaded is low, the GPU's compute cores spend most of their time idle, waiting for the memory controllers to fetch the KV cache. The decode phase is strictly memory-bandwidth bound.
The KV Cache Growth Equation
To size the VRAM requirements of LLM serving, we can model the KV cache size using the following calculation:
KV Cache Size (Bytes) = 2 * B * L * H_kv * D * P
Where:
2represents the separate matrices for Key and Value.Bis the active batch size.Lis the sequence length (prompt length + generated tokens).H_kvis the number of KV heads in the model.Dis the dimension of each head.Pis the precision format in bytes (e.g., 2 bytes for FP16/BF16, 1 byte for FP8).
Consider a model with Grouped-Query Attention (GQA) like Llama 3 8B, which has H_kv = 8 KV heads and a head dimension D = 128. Serving this model at FP16 precision (P = 2) with an active batch size of 64 and a sequence length of 8192 tokens requires:
KV Cache Size = 2 * 64 * 8192 * 8 * 128 * 2 = 2,147,483,648 bytes = 2.15 GB
If we use standard Multi-Head Attention (MHA) where H_kv = H_q = 32 (similar to Llama 2 7B) under the same serving parameters, the cache size quadruples:
KV Cache Size = 2 * 64 * 8192 * 32 * 128 * 2 = 8,589,934,592 bytes = 8.59 GB
As we scale context windows to 32K or 128K, or run serving infrastructures under high concurrent loads, the KV cache size rapidly exceeds the total VRAM capacity of the GPU.
Memory Waste Types
In traditional LLM serving systems, three forms of memory waste severely limited concurrency:
- Internal Fragmentation: Occurs when VRAM is pre-allocated for the maximum sequence length (e.g., 4096 tokens), but the user's request completes after generating only 200 tokens. The remaining space (3896 tokens) remains allocated and completely unused.
- External Fragmentation: Occurs when the memory manager allocates contiguous blocks of varying sizes. As requests finish at different times, they leave small, disjoint gaps of free memory. Even if the total free memory is large enough to host a new request, the engine cannot use it because the free memory is not contiguous.
- Reservation Waste: Occurs when the engine reserves space for the future tokens that a request might generate. This space remains empty and locked during the current iteration, preventing other requests from using it.
Together, these factors resulted in 60% to 80% memory waste in early LLM serving platforms. By introducing virtual memory concepts, PagedAttention reduces this waste to near-zero (less than 4%), allowing the engine to increase batch sizes by 2x to 4x on the same hardware.
Memory Consumption Comparison
Below is a comparison of memory requirements for different model architectures under MHA and GQA configurations.
| Model Architecture | KV Heads | Head Dimension | Sequence Length | Batch Size | VRAM Needed (FP16) | VRAM Needed (FP8) |
|---|---|---|---|---|---|---|
| Llama 2 7B (MHA) | 32 | 128 | 4,096 | 32 | 1.07 GB | 0.54 GB |
| Llama 2 7B (MHA) | 32 | 128 | 8,192 | 64 | 8.59 GB | 4.30 GB |
| Llama 3 8B (GQA) | 8 | 128 | 8,192 | 64 | 2.15 GB | 1.07 GB |
| Llama 3.1 8B (GQA) | 8 | 128 | 16,384 | 128 | 8.59 GB | 4.30 GB |
| Llama 3 70B (GQA) | 8 | 128 | 8,192 | 64 | 2.15 GB | 1.07 GB |
| Llama 3 70B (GQA) | 8 | 128 | 32,768 | 32 | 4.30 GB | 2.15 GB |
⚙️ How It Works
Combining Continuous Batching and PagedAttention requires a unified scheduler and memory manager that synchronizes execution states on a step-by-step basis.
Continuous Batching Scheduling Mechanics
Continuous batching engines replace the standard request-level FIFO queues with dynamic iteration-level schedulers. The scheduler tracks each request as a state machine:
[Waiting Queue] ---> (Prefill Phase) ---> (Decode Phase) ---> [Finished]
^ |
| | (Preemption if VRAM Full)
+-------------------+
During each iteration, the scheduler evaluates the current batch and the waiting queue:
- Prefill Prioritization: The engine prioritizes running the prefill phase for new requests because computing prompts in bulk maximizes Tensor Core efficiency.
- Decode Execution: Active requests in the decode phase are stepped forward by generating one token.
- Dynamic Eviction: If a request generates an end-of-sequence (
EOS) token or reaches its user-definedmax_tokenslimit, the scheduler immediately stops its execution, copies the output text to the user API response, and marks its KV cache blocks as free.
If GPU memory is exhausted due to high traffic, the scheduler must preempt active requests. The engine can handle preemption in two ways:
- Recomputation: The engine evicts a request, frees its physical KV cache blocks, and restarts it from the beginning when VRAM becomes available.
- Swapping: The engine evicts a request and copies its physical KV cache blocks from the fast GPU VRAM to the slower CPU system RAM. When VRAM is freed, the engine swaps the blocks back to the GPU to resume generation.
PagedAttention Block Allocation and Page Tables
PagedAttention implements virtual memory management through a set of logical and physical constructs:
- Logical Blocks: The sequence of tokens generated for a request is divided into logical blocks. If the block size is
B_size = 16, tokens0to15map to Logical Block0, tokens16to31map to Logical Block1, and so on. - Physical Blocks: The physical KV cache memory on the GPU is pre-allocated as a pool of flat, non-contiguous memory blocks during engine startup.
- Block Table: For each request, the engine maintains a Block Table that maps logical blocks to physical blocks.
Logical Blocks (Request A):
[ Block 0 (Tokens 0-15) ] --> Maps to --> Physical Block 104 (VRAM)
[ Block 1 (Tokens 16-31) ] --> Maps to --> Physical Block 87 (VRAM)
[ Block 2 (Tokens 32-47) ] --> Maps to --> Physical Block 212 (VRAM)
During the decode step, the engine executes a custom CUDA attention kernel. Instead of assuming the KV cache is contiguous in memory, the kernel reads the Block Table. For each token position, it computes the block index:
block_idx = token_pos / Block_Size
block_offset = token_pos % Block_Size
The kernel retrieves the physical VRAM address of the target physical block from the Block Table, applies the offset, and loads the Key and Value vectors into GPU registers.
This on-demand block allocation allows multiple requests to share physical blocks. For example, during parallel sampling (generating multiple responses from the same prompt), the physical blocks containing the prompt's KV cache are mapped to the Block Tables of all child requests. The engine only copies the blocks when a child request begins generating its own unique tokens. This is known as Copy-on-Write (CoW) memory sharing.
🏛️ Architecture
Different inference engines have adopted distinct architectural approaches to implement and optimize these memory management techniques. We focus on the three primary production-grade engines: vLLM, Hugging Face Text Generation Inference (TGI), and SGLang.
vLLM
vLLM, developed by UC Berkeley, is the pioneer of PagedAttention.
- V1 vs. V2 Engines: Early vLLM versions relied heavily on Python for request scheduling and block coordination, which introduced orchestration overhead. In late 2025/2026, vLLM introduced its V1 engine architecture and Model Runner V2 (MRv2). The orchestration, request routing, and page management were moved to a C++ backend, while the Python frontend is kept for API routing and model definition.
- Hardware Agnosticism: vLLM has evolved to support a wide range of hardware, including NVIDIA GPUs (using optimized Triton and custom CUDA kernels), AMD ROCm, Intel Gaudi, and Google TPUs.
- Multi-Node Serving: vLLM natively scales across multiple GPUs using Ray or Megatron-LM tensor parallelism and pipeline parallelism.
Hugging Face Text Generation Inference (TGI)
Hugging Face TGI was one of the earliest production servers for LLMs, built as a hybrid Rust and Python application.
- Rust Orchestrator: Unlike early Python-bound engines, TGI used a high-performance Rust web server to handle connection queuing, continuous batching execution, and streaming responses, which minimized latency.
- Memory Management: TGI originally relied on traditional contiguous allocation but later integrated custom attention kernels like FlashAttention, PagedAttention, and vLLM's memory manager blocks.
- Maintenance Status: By mid-2026, Hugging Face TGI has shifted into a stable maintenance mode. Development has slowed down compared to vLLM, and the broader community recommends migrating new production deployments to vLLM or SGLang for better throughput and performance.
SGLang
SGLang is designed specifically for complex agentic workflows, multi-turn conversations, and structured JSON generation.
- RadixAttention: Instead of using standard linear page tables, SGLang manages the KV cache as a prefix tree (a Radix Tree). When a user sends a prompt, SGLang checks if any prefix of the prompt (e.g., system instructions or few-shot examples) is already present in the radix tree. If a match is found, SGLang reuses the existing physical blocks directly, bypassing the prefill compute phase. This reduces Time to First Token (TTFT) by up to 90% for repetitive prompts.
- Structured Generation: SGLang includes a compiler and runtime that optimizes constrained decoding (e.g., forcing the model to output valid JSON or match a regex), using compressed finite-state machines to execute structured sampling directly within the runtime.
Inference Engine Comparison
The following table compares the design choices and features of the three engines.
| Architectural Feature | vLLM (2026 / Stable) | SGLang (2026 / Active) | HF TGI (2026 / Maintenance) |
|---|---|---|---|
| Orchestration Language | C++ Backend / Python API | Python (Fast-path runtime) | Rust (Core) / Python (Model) |
| KV Cache Structure | PagedAttention Block Tables | RadixAttention Prefix Tree | Custom Paged / FlashAttention |
| Prefix Caching | Logical prefix hash matching | Dynamic Radix Tree sharing | Exact prefix match caching |
| Structured Output | Outlines / Guidance libraries | Native compiled constraint FSM | JSON Schema validation |
| Hardware Support | NVIDIA, AMD, TPU, Gaudi, CPU | NVIDIA, AMD ROCm | NVIDIA, AMD ROCm |
| Primary Optimization | Raw throughput, scaling | Low TTFT, Agentic workflows | Latency, Ecosystem stability |
🛠️ Production Deployment Considerations
Deploying these engines in production requires careful tuning of memory allocation parameters to prevent out-of-memory errors while maximizing concurrent throughput.
Tuning the Memory Pool
The primary parameter in vLLM is gpu_memory_utilization (defaulting to 0.9). This controls the fraction of total GPU VRAM that the engine allocates. During startup, the engine performs the following memory allocation:
VRAM Allocation = Model Weights Memory + KV Cache Memory Pool + PyTorch/CUDA Workspace
If you deploy a Llama 3 8B model (which takes ~16 GB in FP16) on an A100 80GB GPU, setting gpu_memory_utilization = 0.9 reserves 72 GB of VRAM. The remaining 8 GB is left for the operating system and dynamic CUDA workspaces. The engine allocates the KV cache memory pool from the remaining space after model weights are loaded:
KV Cache Pool = (Total VRAM * gpu_memory_utilization) - Model Weights
KV Cache Pool = 72 GB - 16 GB = 56 GB
This 56 GB pool is partitioned into physical blocks. If the block size is 16, each block stores 16 tokens of Key and Value vectors for all layers. For Llama 3 8B (32 layers, 8 KV heads, 128 head dimension, FP16 precision):
Block Size (Bytes) = 2 * 16 * 8 * 128 * 2 * 32 = 2,097,152 bytes = 2.09 MB
With 56 GB available, the engine allocates approximately 26,800 physical blocks, which can store a total of 428,800 active tokens across all concurrent batches.
Configuring vLLM Production Parameters
To optimize throughput under varying traffic patterns, configure the following settings in your vLLM launcher script:
--gpu-memory-utilization: Adjust this value based on your serving setup. For dedicated production containers with no other workloads, set it to0.90or0.95. If you observe random CUDA OOM errors during the prefill phase, reduce it to0.85.--max-model-len: Limit the maximum sequence length. For example, if a model supports 32K context but your business application only requires 8K, limit this parameter to8192. This prevents users from sending massive prompts that exhaust the block pool.--block-size: Typically set to16or32. A block size of16minimizes internal memory waste but increases the size of the block tables and page lookup overhead. A block size of32reduces lookup overhead but can increase memory waste for short requests.--enable-prefix-caching: Set this toTruefor applications like RAG or multi-turn chat. It enables the engine to cache and reuse the KV cache of system prompts, query templates, and documents.--swap-space: Specifies the CPU memory swap limit (in GB). If VRAM is exhausted, the engine swaps blocks to host CPU memory. Set this to16or32to provide a safety buffer against traffic spikes, but avoid relying on it heavily, as CPU-to-GPU memory transfer introduces high latency.
Multi-GPU Scaling
When scaling to models that do not fit on a single GPU (e.g., Llama 3 70B), configure your parallelization strategy:
- Tensor Parallelism (
--tensor-parallel-size): Splits the model layers horizontally across multiple GPUs. This is highly recommended for low latency because it distributes the computation of each layer. It requires fast interconnects like NVLink. - Pipeline Parallelism (
--pipeline-parallel-size): Splits the model layers vertically across GPUs (e.g., layers 1-40 on GPU 0, layers 41-80 on GPU 1). This is suitable for environments without high-speed NVLink interconnects, but it introduces bubble overhead (idle time) that must be managed using micro-batching.
❌ Common Mistakes
Deploying continuous batching and PagedAttention in production often leads to several common configuration errors:
1. Over-Allocating gpu_memory_utilization
Setting gpu_memory_utilization to 0.98 or 1.0 in an attempt to maximize the KV cache size often backfires. During the prefill phase, PyTorch requires temporary workspace memory to compute intermediate attention scores. If the KV cache pool occupies almost all VRAM, these temporary allocations will fail, triggering a CUDA out-of-memory (OOM) crash.
2. Mismatching Block Sizes
Configuring a block size that is not aligned with the GPU's memory controllers or the attention kernel's tiling sizes can hurt performance. For example, setting an arbitrary block size like 8 or 24 can break alignment, forcing the CUDA kernel to perform unaligned memory reads, which reduces throughput. Stick to the standard values: 16 or 32.
3. Disabling Prefix Caching on Repetitive Prompts
In Retrieval-Augmented Generation (RAG) pipelines, developers often insert large reference documents into the prompt template. If prefix caching is disabled, the engine must recompute the attention keys and values for these documents for every single request, wasting valuable GPU compute cycles and increasing TTFT.
4. Ignoring Chunked Prefills
When a massive user prompt (e.g., 32,000 tokens) enters a running batch of decode requests, it can cause a "prefill bubble." The engine must pause the decode iterations of the other requests to process the large prompt, resulting in a spike in inter-token latency. Enabling chunked prefills (--enable-chunked-prefill=True) splits large prompts into smaller chunks, allowing prompt prefill and token generation to run in parallel.
📈 Lessons From Production Deployments
Operating large-scale LLM API clusters in production has revealed several key insights:
The Real Cost of CPU Swapping
While setting --swap-space=16 prevents the engine from crashing during sudden traffic spikes, relying on swapping to handle sustained high load is impractical. Transferring KV cache blocks over PCIe Gen 4/5 interfaces is orders of magnitude slower than reading them from HBM. Under heavy swapping, the engine's throughput drops by over 80%, and inter-token latency spikes, leading to a poor user experience. Swapping should only be used as a temporary safety buffer, not as a core scaling mechanism.
Python GIL Bottlenecks in Multi-Tenant Environments
Under high concurrency (hundreds of requests per second), SGLang and early vLLM setups can encounter CPU bottlenecks. Because these engines run scheduling logic in Python, the Global Interpreter Lock (GIL) can prevent the system from scaling across multiple CPU cores, even if the GPU remains underutilized. Moving to vLLM's V1 engine with its C++ backend helps resolve this bottleneck by decoupling request scheduling from Python execution.
CUDA Driver and Docker Version Drift
A common operational issue in Kubernetes environments is version drift between the GPU drivers on the host machine and the CUDA libraries inside the Docker container. This can lead to silent performance degradation or failures in custom CUDA kernels (such as the PagedAttention page-table kernel). Always ensure that your containerized CUDA version is fully compatible with your host's NVIDIA drivers.
Hugging Face TGI Migration Path
As Hugging Face TGI has shifted to maintenance mode, many organizations are migrating their infrastructure to vLLM or SGLang. During migration, ensure you verify compatibility with custom models and adapter routing. SGLang is often chosen for multi-turn chat applications due to its prefix caching, while vLLM is preferred for standard API endpoints due to its stable scaling and broad model support.
🔍 What Most Articles Miss
While many guides explain the basics of PagedAttention, they often overlook key technical challenges and trade-offs.
KV Cache Quantization Trade-offs (FP8 vs. FP4)
To reduce the VRAM footprint of the KV cache, modern engines support quantizing the cache to 8-bit (FP8) or 4-bit (FP4) precision.
FP8 Cache Size (Bytes) = B * L * H_kv * D * 1
FP4 Cache Size (Bytes) = B * L * H_kv * D * 0.5
Quantizing the KV cache to FP8 reduces memory consumption by 50% compared to FP16, allowing you to double the batch size. However, this compression introduces quantization noise, which can degrade model quality in tasks requiring high precision, such as writing code or solving math problems.
Furthermore, FP8 and FP4 operations require runtime dequantization scale factors, which can introduce overhead on older GPU architectures (e.g., NVIDIA Ampere/A100) that lack native hardware support for low-precision operations.
Page Allocation Table Synchronization Latency
As the batch size scales, the engine must constantly update the page table, allocating and deallocating physical blocks. This synchronization between the host CPU (where the scheduler runs) and the GPU (where the attention kernel executes) can introduce latency jitter. Under heavy loads, these page table updates can cause spikes in tail latency (p99), even if average latency remains low.
The Prefix Cache Eviction Strategy
Prefix caching relies on an LRU (Least Recently Used) eviction policy. When the GPU runs out of VRAM, the engine evicts the least recently used prompt prefixes. If your application has highly diverse traffic, the prefix cache hit rate can drop to near-zero, causing the engine to spend extra CPU cycles managing the cache tree without any actual performance benefit. In such scenarios, disabling prefix caching can save CPU overhead.
🎯 Best Practices
To ensure high-throughput and reliable performance, follow these guidelines when deploying LLM serving infrastructures:
- Limit Max Sequence Length: Configure
--max-model-lento match your application's actual needs, rather than using the model's theoretical maximum. - Enable Chunked Prefills: Use
--enable-chunked-prefill=Trueon high-concurrency endpoints to prevent large prompts from blocking active generation requests. - Optimize GPU Utilization: Set
--gpu-memory-utilizationto0.90or0.95for dedicated inference nodes. Reduce the setting if you encounter unexpected CUDA out-of-memory errors. - Use Prefix Caching for RAG: Always enable prefix caching (
--enable-prefix-caching) when serving applications with large, repetitive prompt contexts. - Match Block Size to Architecture: Stick to standard block sizes of
16or32to ensure proper memory alignment and optimal kernel execution. - Monitor Cache Hit Rates: Track your prefix cache hit rates and request queue lengths to determine whether you need to adjust your VRAM allocation or scale your GPU cluster.
❓ FAQ
1. What is the main difference between continuous batching and static batching?
Static batching processes a fixed group of requests and waits for all of them to complete before starting a new batch. Continuous batching schedules execution at the token iteration level, dynamically evicting finished requests and inserting new ones after every generation step, which keeps the GPU utilized.
2. How does PagedAttention eliminate memory fragmentation?
PagedAttention divides the KV cache into fixed-size blocks (typically representing 16 or 32 tokens) and maps them to physical GPU memory using a page table. Because these blocks do not need to be contiguous in physical memory, it eliminates the need to pre-allocate large, contiguous blocks of VRAM, reducing memory waste to near-zero.
3. Does PagedAttention affect model accuracy?
No. PagedAttention is a memory management technique that does not change the mathematical output of the attention mechanism. It only changes how the Key and Value vectors are stored and accessed in VRAM.
4. What is SGLang's RadixAttention, and how does it compare to PagedAttention?
PagedAttention maps logical token sequences to physical memory blocks. SGLang's RadixAttention builds on this by managing the page table as a radix tree (prefix tree). This allows SGLang to identify and reuse shared prompt prefixes (such as system instructions) across different requests, avoiding redundant prefill computation.
5. When should I choose vLLM over Hugging Face TGI?
As of mid-2026, Hugging Face TGI is in maintenance mode. vLLM is the recommended choice for most production deployments due to its active development, broad hardware support, mature ecosystem, and high performance.
6. What is the impact of KV cache quantization (FP8/FP4)?
Quantizing the KV cache to FP8 or FP4 reduces its memory footprint by 50% or 75%, respectively. This allows you to increase batch sizes and throughput on the same hardware, but it can introduce quantization noise that slightly degrades model accuracy in complex tasks.
7. Why do I get CUDA out-of-memory (OOM) errors even when using PagedAttention?
This usually occurs because --gpu-memory-utilization is set too high (e.g., 0.98), leaving insufficient VRAM for the temporary workspace memory required during the prefill phase. Reducing the setting to 0.85 or 0.90 typically resolves the issue.
8. What is a prefill bubble, and how can I prevent it?
A prefill bubble occurs when a large prompt enters the execution batch, causing the engine to pause ongoing token generation to process the new prompt. This leads to a spike in latency for the active requests. You can prevent this by enabling chunked prefills (--enable-chunked-prefill=True), which splits large prompts into smaller chunks.
9. Does PagedAttention work on non-NVIDIA GPUs?
Yes. Modern engines like vLLM support running PagedAttention on AMD ROCm, Google TPUs, Intel Gaudi, and CPUs by using optimized Triton kernels or hardware-specific backends.
10. How does CPU swapping affect performance?
CPU swapping allows the engine to swap KV cache blocks to host CPU memory when GPU VRAM is full. However, transferring data over PCIe interfaces introduces high latency, which can cause inter-token latency to spike. Swapping should only be used as a safety buffer against traffic spikes.
🎯 Key Takeaways
- Memory Is the Bottleneck: Large language model decoding is memory-bandwidth bound. Optimizing how the Key-Value (KV) cache is stored and accessed is critical for improving throughput.
- Iteration-Level Scheduling: Continuous batching eliminates the "last token problem" of static batching by dynamically inserting new requests into the batch as soon as others finish.
- Virtual Memory for VRAM: PagedAttention solves KV cache fragmentation by managing VRAM in fixed-size blocks (pages) mapped through page tables, reducing memory waste from 80% to less than 4%.
- Engine Choices in 2026: vLLM remains the industry standard for high-throughput API serving. SGLang is optimized for low latency and agentic workflows, while Hugging Face TGI is in maintenance mode.
- Use Prefix Caching: Enabling prefix caching is essential for applications like RAG or multi-turn chat, as it allows the engine to reuse the KV cache of common prompt prefixes.
- Tune Production Parameters: Always configure
--max-model-len,--gpu-memory-utilization, and chunked prefills based on your specific model architecture and traffic patterns to ensure stable and high-performance serving.
