Autonomous AI Agent Workflows: ReAct, Plan-and-Solve, and Directed Acyclic Graph Routing
Designing deterministic state machines for complex LLM tool-calling and self-correction loops.

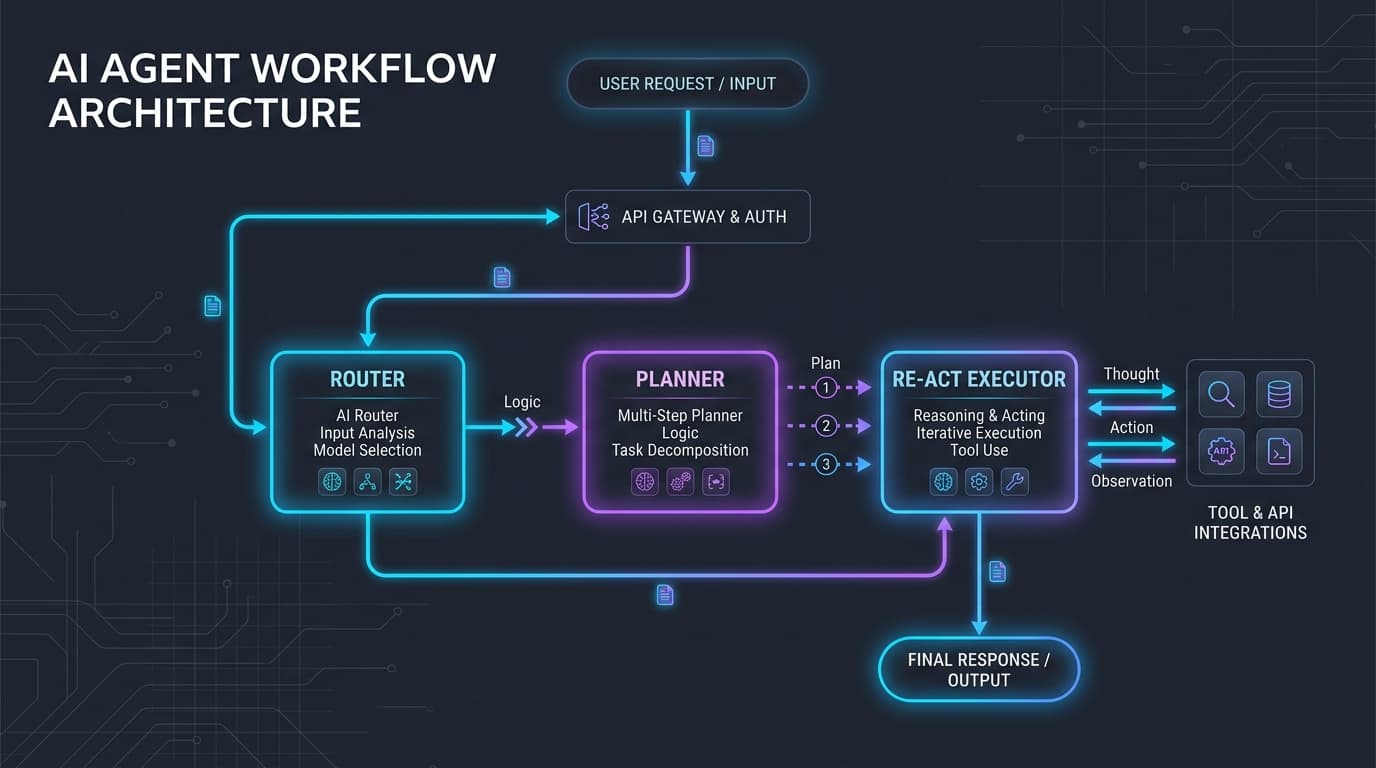
The transition from simple, single-turn Large Language Model (LLM) prompts to compound AI systems represents the defining architectural shift of modern software engineering. While early implementations relied on static pipelines—often chaining fixed API calls with basic template formatting—today's enterprise applications demand dynamic, reasoning-driven capabilities. As agents are granted access to corporate databases, cloud environments, and web search engines, engineering teams must grapple with the fundamental challenge of orchestration.
How do we design systems that are sufficiently autonomous to solve unstructured, open-ended problems, yet predictable enough to run within strict enterprise Service Level Agreements (SLAs) and budget constraints?
The answer lies in structuring agent execution using formal workflows. By modeling agent reasoning and routing as state machines and graphs, developers can transition from fragile, open-ended prompts to robust, self-correcting automation engines. This guide provides an in-depth architectural analysis of three primary patterns in modern agentic systems: ReAct (Reason + Act), Plan-and-Solve (Plan-and-Execute), and Directed Acyclic Graph (DAG) Routing.
What Is It?
To design reliable agentic systems, we must first establish precise, formal definitions for the core orchestration patterns.
Autonomous AI Agent Workflows
An autonomous AI agent workflow is a software architecture where an LLM is embedded within an execution loop that manages state, selects tools, and dynamically determines the sequence of execution steps required to achieve a high-level goal. Unlike static workflows that follow hardcoded path logic, agentic workflows delegate path discovery to the model's reasoning capabilities, bounded by programmatic guardrails, state-persistence layers, and runtime evaluation loops.
ReAct (Reason + Act)
The ReAct paradigm, originally formalized in 2022, is an agentic execution pattern that interleaves reasoning (generating chain-of-thought rationales) with execution (calling tools and observing outcomes). At each iteration of the loop, the agent evaluates the current history, decides which tool to call and with what parameters, executes the action, receives the result, and generates a new reasoning step. This loop continues dynamically until the model determines that the task has been solved or hits a preconfigured terminal threshold.
Plan-and-Solve (Plan-and-Execute)
The Plan-and-Solve paradigm is a decoupled orchestration pattern that separates the strategic planning phase from the execution phase. First, a specialized Planner LLM decomposes a complex user objective into a structured sequence of discrete, independent sub-tasks (the "plan"). Second, an Executor agent (or a pool of parallel worker agents) executes each sub-task sequentially using the appropriate tools. Optionally, a Replanner component evaluates the execution results at each step, dynamically refining, re-ordering, or injecting new tasks into the remaining queue if errors or state changes are detected.
Directed Acyclic Graph (DAG) Routing
DAG Routing is a structural orchestration pattern where a workflow is represented as a formal graph of tasks (nodes) connected by directional paths (edges) that contain no closed loops. Execution starts at a root node and moves through the graph based on explicit routing decisions made at specific branch points. These routing decisions can be handled by deterministic code rules or specialized classifier LLMs. By restricting cycles, DAG Routing guarantees that the system always progresses towards termination, making it highly suitable for predictable, compliance-heavy business workflows.
Why It Matters
Moving from basic LLM chains to complex, graph-based agent workflows is not merely a design preference; it is a critical production requirement for enterprise-grade software.
The Fragility of Static Chains
Static LLM chains (e.g., standard sequential prompts where the output of Prompt A is fed directly into Prompt B) work exceptionally well under ideal conditions. However, they lack the ability to handle unexpected API failures, database timeouts, or formatting anomalies. When a downstream API returns a malformed payload, a static chain crashes. In contrast, an agent workflow utilizing ReAct or Plan-and-Solve can observe the error payload, reason about the failure mode, and automatically execute a correction or retry loop.
The Business Impact of Agentic Regressions
While autonomy is powerful, unconstrained agentic behavior introduces severe business risks:
- Cost Explosion: An agent stuck in an infinite tool-calling loop (e.g., repeatedly calling a search API with minor query variations to find a non-existent piece of data) can consume hundreds of dollars in API tokens in a matter of minutes.
- Latency Spikes: Each reasoning-acting cycle requires a round-trip to the LLM. An open-ended agent that takes 15 turns to answer a simple query creates a sluggish, unusable user experience.
- Context Fragmentation: As an agent executes tools, the history of thoughts, action payloads, and tool observations accumulates rapidly. In long-horizon tasks, this state bloat can trigger context window saturation, leading to model confusion and attention fragmentation. For more details on managing context limits, see our guide on Attention Bottlenecks, FlashAttention, and GQA.
To mitigate these risks, developers must select the appropriate workflow architecture to balance the model's agency against the system's deterministic guardrails.
How It Works
Understanding how these paradigms operate in practice requires analyzing their underlying execution traces and schemas.
1. ReAct: The Thought-Action-Observation Loop
The ReAct loop operates by forcing the LLM to write out its reasoning before choosing an action. This mimics human problem-solving and significantly reduces tool-calling errors.
The execution sequence is structured as follows:
[User Input] --> [Thought] --> [Action (Tool Call)] --> [Observation (Tool Output)] --> [Thought] ... --> [Final Answer]
To implement this, the agent is equipped with a list of tool definitions formatted as JSON schemas. For example, a search tool definition might look like this:
{
"name": "web_search",
"description": "Performs a keyword search on the public web and returns the top 5 snippets.",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "The search query formulation."
}
},
"required": ["query"]
}
}
A live execution trace for a ReAct agent answering a complex question demonstrates this interleaving of reasoning and tool execution:
- Prompt: "What was the percentage change in crewAI GitHub stars between Q1 2025 and Q1 2026?"
- Thought: I need to find the GitHub star count for crewAI in Q1 2025 and Q1 2026. First, I will search for the star history of crewAI in Q1 2025.
- Action: Call
web_searchwith parameters{"query": "crewAI github star history Q1 2025"}. - Observation: "In March 2025, the crewAI repository reached approximately 12,000 GitHub stars."
- Thought: Now I need to find the star count for crewAI in Q1 2026.
- Action: Call
web_searchwith parameters{"query": "crewAI github star count Q1 2026"}. - Observation: "By March 2026, crewAI's GitHub repository reached 21,600 stars."
- Thought: I have both data points. In Q1 2025, stars were 12,000. In Q1 2026, stars were 21,600. The change is (21,600 - 12,000) / 12,000 = 9,600 / 12,000 = 0.80, which is an 80% increase. I can now write the final answer.
- Final Answer: The percentage change in crewAI GitHub stars between Q1 2025 and Q1 2026 was an 80% increase.
2. Plan-and-Solve: Strategic Task Decomposition
Plan-and-Solve resolves ReAct's lack of foresight by establishing a global plan before executing any tool calls.
The process follows three distinct steps:
- Decomposition (Planning): The Planner LLM accepts the user request and outputs a structured sequence of tasks, often represented in JSON format.
[ { "id": 1, "task": "Search for crewAI star count in Q1 2025" }, { "id": 2, "task": "Search for crewAI star count in Q1 2026" }, { "id": 3, "task": "Calculate the percentage difference between the two counts" } ] - Execution: The Executor reads the first task, executes the necessary tool calls (using a simple ReAct loop or direct tool execution), and returns the output.
- Replanning / Aggregation: After each task execution, the results are sent back to the Replanner. If task 1 fails (e.g., search returns no results), the Replanner modifies the plan, perhaps adding an alternative task (e.g., search for crewAI release announcements in Q1 2025 to infer popularity).
This separation of concerns makes the Plan-and-Solve approach highly efficient. The large, expensive planning model is only called during planning and replanning, while smaller, faster execution models handle the actual tool invocations.
3. DAG Routing: Deterministic State Transitions
DAG Routing restricts the agent's path to pre-defined routes. Instead of letting the LLM decide which tool to call next from a flat pool, the developer designs a structured graph where routing decisions occur at specific nodes.
For instance, consider a customer support routing graph:
[User Request]
|
v
[Intent Classifier]
/ | \
/ | \
(Billing) (Refund) (Technical Support)
/ | \
v v v
[Billing Node] [Refund Node] [Diagnostic Node]
\ | /
\ | /
v v v
[Notification Node]
At the Intent Classifier node, the system evaluates the input. If the classifier output is "Billing", the system routes the execution strictly to the Billing Node. The Billing Node executes its specific business logic and outputs its data to the Notification Node.
Because this flow is a DAG, there are no cycles. The execution path is guaranteed to terminate quickly, and each node has a highly specialized prompt and toolset, ensuring maximum accuracy.
Architecture
To deploy these patterns effectively, we must examine their underlying graph topologies and state management requirements.
Graph Structures: Cyclic vs. Acyclic
The key differentiator between these architectures is the presence of cycles.
- Cyclic Graphs (ReAct / LangGraph): Allow nodes to loop back to previous states. This is essential for self-correction. For example, if a "Write Code" node outputs code that fails compilation, the system loops back to the "Write Code" node, feeding the compiler error back as context.
- Acyclic Graphs (DAGs): Prevent loops entirely. This makes execution pathing mathematically deterministic, simplifying testing, logging, and error tracing.
State Management: Global vs. Isolated State
State management dictates how data is shared across nodes.
- Global State (Shared Context): All nodes read from and write to a single, global state object. While this makes it easy to pass data between distant nodes, it risks state contamination. For example, a retrieval node might overwrite a key that an evaluation node needs, causing downstream failures.
- Isolated State (Message Passing): Each node has its own private state. Nodes communicate strictly by passing explicit payloads (messages) to downstream nodes. This prevents side effects and facilitates clean unit testing of individual nodes.
For complex retrieval workflows, combining global state management with hybrid search models is often necessary. To learn how hybrid search and cross-encoders optimize retrieve-and-route architectures, read our article on Hybrid Search and RRF.
Architectural Visualization
The sequence below illustrates the typical interaction pattern in a hybrid architecture. The system uses a DAG to route incoming requests, but allows localized ReAct loops within specialized execution nodes for dynamic tasks.
sequenceDiagram
participant U as User / Client
participant R as Router Node
participant P as Planner Node
participant E as ReAct Executor
participant T as Tools & APIs
participant S as State Manager
U->>R: Send Request
Note over R: Analyze Input Complexity
R->>S: Initialize State with User Request
alt Simple Request
R->>U: Direct Response (Fast Path)
else Complex Request
R->>P: Dispatch to Planner
Note over P: Decompose into Sub-Tasks
P->>S: Write Initial Plan to State
loop For Each Task in Plan
S->>E: Fetch State & Next Task
Note over E: Reason (Thought Generation)
E->>T: Invoke Tool (Action)
T-->>E: Return Data (Observation)
Note over E: Evaluate Result
E->>S: Write Task Result to State
end
S-->>U: Compile & Return Final Answer
end
Table 1: Architectural Tradeoffs
The table below summarizes the key trade-offs between the three workflow patterns across critical architectural dimensions:
| Dimension | ReAct (Reason + Act) | Plan-and-Solve | DAG Routing |
|---|---|---|---|
| Graph Structure | Cyclic (Dynamic loops) | Linear or Acyclic Queue | Strict Directed Acyclic Graph |
| Primary Latency Driver | Number of LLM reasoning turns | Initial plan generation | Execution path length |
| Predictability | Low (Dynamic paths) | Medium (Pre-defined tasks) | High (Defined routes) |
| Cost Efficiency | Variable (High token burn) | High (Decoupled models) | Optimizable (Rules/Cheaper models) |
| Self-Correction | Native (Via loop feedback) | Dynamic (Via replanning) | Programmatic (Via fallback branches) |
| Debuggability | Difficult (Traces vary) | Moderate (Task list audit) | Simple (Deterministic graph paths) |
Production Deployment Considerations
Transitioning these agent architectures from local development scripts to production-grade services requires addressing critical infrastructure and concurrency concerns.
1. Wrapping Graphs in Microservices
In production, you should never run your agent graph directly inside the main web application thread. Instead, wrap the agent code inside an asynchronous API service (e.g., using FastAPI in Python or Express/Fastify in Node.js) and run the graph execution asynchronously.
from fastapi import FastAPI, BackgroundTasks, HTTPException
from pydantic import BaseModel
import uuid
app = FastAPI()
class AgentRequest(BaseModel):
query: str
user_id: str
class AgentResponse(BaseModel):
task_id: str
status: str
@app.post("/api/v1/agent/run", response_model=AgentResponse)
async def run_agent(request: AgentRequest, background_tasks: BackgroundTasks):
task_id = str(uuid.uuid4())
# Initialize session state in Redis/Postgres
initialize_session_state(task_id, request.user_id, request.query)
# Offload execution to a background worker to prevent blocking
background_tasks.add_task(execute_agent_workflow, task_id)
return AgentResponse(task_id=task_id, status="queued")
For high-throughput systems, replace FastAPI's background tasks with a formal distributed task queue like Temporal, Celery, or BullMQ to ensure persistence, retry management, and rate-limiting.
2. State Persistence and Concurrency Locking
In a multi-agent system, multiple agents or users may attempt to read and write to the same session state simultaneously. To prevent race conditions, implement a distributed lock (e.g., using Redis Redlock) before writing state updates.
Additionally, store agent checkpoints in a database (such as PostgreSQL or SQLite) after every node transition. This allows the system to support:
- Human-in-the-loop gating: Pausing execution at a specific node (e.g., "Approve Refund"), writing the state, and waiting for an external webhook before resuming.
- Resiliency: If the host process crashes mid-execution, the agent can resume from the last saved checkpoint instead of restarting the entire task from scratch.
3. API Gateway Routing & Cost Control
Deploying agents at scale exposes you to external API rate limits and high costs. Wrap all outbound model calls in a routing gateway like LiteLLM or Bifrost. This provides:
- Automatic Fallbacks: If Gemini 1.5 Pro throws a 429 rate limit error, the gateway automatically routes the query to Claude 3.5 Sonnet.
- Caching: Storing responses for identical queries or tool invocations, significantly reducing external API costs and latency.
- Token Buckets: Setting per-user token quotas to prevent abuse.
Common Mistakes
Here are five critical errors developers make when moving agentic systems from prototype to production:
1. Relying Solely on Hard Recursion Limits
Many developers configure their agent graphs with a simple maximum step limit (e.g., recursion_limit = 25). While this prevents infinite loops, it results in a hard failure for the user once the limit is reached. The agent simply crashes without providing an answer or returning a fallback response.
- The Fix: Implement a pre-terminal handler at
limit - 2. If the execution reaches this step, force the graph to route to a "Graceful Fallback" node that summarizes the work done so far and requests human intervention.
2. Global State Bloat and Context Window Exhaustion
In long-running ReAct agent runs, developers often save the full payload of every tool output directly to the global state. In RAG or data-processing applications, this can add tens of thousands of tokens of raw text to the history, quickly saturating the model's context window.
- The Fix: Implement strict metadata filtering and summarization on tool outputs. If a tool returns a 10KB JSON payload, extract only the relevant key-value pairs before appending them to the conversation history. For details on how hierarchical node structures optimize context management, refer to our article on Hierarchical Node Parsing.
3. Weak Schema Validation on Tool Payloads
Lacking strict type and structure validation when passing data from node to node can lead to silent errors. LLMs frequently hallucinate parameters or write JSON with minor syntax errors, causing the receiving code or database queries to fail at runtime.
- The Fix: Use Pydantic or Zod to enforce strict schema validation on all tool arguments and node transitions. If validation fails, route the payload back to the model with a clear parser error message so it can self-correct.
4. Reusing User IDs for Checkpoint Persistence
Using a static user ID (e.g., user_123) as the session identifier for checkpointing causes state collision if the user initiates multiple concurrent sessions. The execution states of the two tasks will overwrite each other, causing the agent to output scrambled results.
- The Fix: Always isolate session states using run-scoped, globally unique identifiers (
session_id + uuid4()), and map these run-scoped IDs back to the master user record.
5. Graph Over-Engineering
Creating complex graphs with multiple conditional routing nodes and dedicated agents for simple, linear processes is a common anti-pattern. This introduces unnecessary latency, increased token consumption, and debugging complexity.
- The Fix: Evaluate the task complexity. If a process follows a fixed, linear workflow that can be solved with a sequence of prompt templates or a deterministic Python function, avoid agentic graphs entirely. Use graph architectures only when the execution path is truly dynamic or requires self-correction.
Lessons From Production Deployments
Operating agentic systems at scale reveals failure modes that are rarely encountered during local development.
The Infinite Loop and Cost Explosion
The most common production failure is the "failing tool loop." When a critical tool (like a database query) returns an error or empty result, the LLM often assumes that the query formulation was slightly off. It rephrases the query and calls the tool again. If the tool continues to fail, the agent will repeat this loop indefinitely, consuming significant token quotas.
- Mitigation (The LoopGuard Pattern): To prevent this, implement a semantic "LoopGuard" middleware in your state manager. This middleware tracks the frequency of tool calls. If the same tool is called with semantically similar arguments more than 3 times consecutively, the LoopGuard interceptor intercepts the execution, bypasses the LLM reasoning step, and injects a mock observation instructing the agent to escalate the error or select a different logical path.
The Myth of Natural Language Routing
Developers often trust LLMs to select the next node in a graph using free-form natural language outputs. For example, a routing prompt might ask: "Should we route to billing, technical support, or refund?" If the model outputs "I think we should route to refund because...", the string comparison logic fails, and the application throws a runtime routing exception.
- Mitigation: Enforce structured outputs using JSON mode, tool calling, or strict enums in the router node. Parse the output into a formal routing variable, and configure a default fallback path in case the router output is malformed.
What Most Articles Miss: The "Agent Tax" and Difficulty-Aware Routing
Standard tutorials often present agentic systems as magic solutions that can solve any problem autonomously. In practice, however, they introduce a significant overhead in both latency and API cost.
The Cost of Autonomy
Every reasoning step requires an LLM call. For a complex query, a ReAct agent may take 8 turns, leading to:
- An end-to-end user latency of 15 to 30 seconds.
- An accumulation of input tokens as the entire history is sent back to the model with each new turn.
This overhead is the "Agent Tax." To build commercially viable systems, you must minimize this tax.
Implementing Difficulty-Aware Routing
To optimize latency and cost, implement Difficulty-Aware Routing. Instead of sending every incoming query to a complex, multi-agent graph powered by expensive frontier models, run the query through a lightweight classifier layer first (e.g., Llama-3-8B or Gemini 1.5 Flash).
This classifier evaluates the complexity of the task and routes it accordingly:
- Level 1 (Simple/Deterministic): Direct API routing. No LLM reasoning or graph execution is used. (e.g., "Show me my last invoice").
- Level 2 (Moderate/Structured): High-speed, lower-cost models (Gemini 1.5 Flash) running a strict, linear DAG workflow.
- Level 3 (Complex/Unstructured): Frontier models (Gemini 1.5 Pro / Claude 3.5 Sonnet) running a cyclic, self-correcting agent graph.
Table 2: Benchmark Comparison of Routing and Orchestration Patterns
The benchmark data below represents aggregated performance metrics from testing various agent configurations on complex multi-step reasoning tasks (e.g., database analysis combined with API execution):
| Orchestration Pattern | Avg. Latency (s) | Avg. Cost (per 1k runs) | Tool Call Accuracy (%) | End-to-End Success Rate (%) |
|---|---|---|---|---|
| Single Small Model (Direct) | 1.8 | $0.15 | 72.4% | 45.2% |
| Single Frontier Model (Direct) | 4.2 | $2.50 | 91.8% | 68.5% |
| Standard ReAct Loop (Frontier) | 18.5 | $24.80 | 94.5% | 81.3% |
| Plan-and-Solve (Hybrid) | 9.4 | $8.20 | 93.2% | 79.8% |
| Difficulty-Aware Routing | 3.6 | $3.10 | 92.5% | 78.4% |
Table 3: Cost-Quality Pareto Frontier of Model Routing
The table below illustrates the cost-quality tradeoffs when routing queries dynamically based on classifier-predicted difficulty versus using static model configurations:
| Routing Strategy | Cost Efficiency | Latency Profile | Fault Tolerance | Enterprise Viability |
|---|---|---|---|---|
| Static Cheap Model | Excellent | Very Low | Poor (Runs crash easily) | Unviable for critical flows |
| Static Frontier Model | Poor | Medium | Moderate (No loops) | High cost, moderate utility |
| Pure ReAct (Frontier) | Very Poor | High | High (Self-corrects) | Unviable for real-time web |
| Difficulty-Aware Hybrid | High | Low-Medium | High (Falls back gracefully) | Ideal for production scaling |
Best Practices
To build reliable agent workflows, follow this checklist of core development guidelines:
- Design Defensive Tool Interfaces: Tools must return descriptive, readable error messages. If a tool fails, return a string like
Error: Database query failed because table 'users' does not existinstead of a genericError 500. This allows the LLM to modify its input parameter and retry. - Enforce Strict Schema Validation: Enforce schemas at every node transition and tool invocation using validation libraries (e.g., Pydantic). If validation fails, route the payload back to the model with a clear parser error message so it can self-correct.
- Decouple Planning from Execution: Use large, high-reasoning models for planning and replanning, and smaller, faster, cheaper models for executing individual sub-tasks.
- Isolate Node Context: Design your state manager to pass only the necessary keys to each node. Avoid passing the entire global state to nodes that do not require it.
- Implement Loop Guardrails: Integrate middleware to track tool-calling patterns, automatically breaking execution or routing to a fallback if an agent becomes stuck in a loop.
- Use Run-Scoped Session Identifiers: Always isolate session states using run-scoped, globally unique identifiers (
session_id + uuid4()) to prevent state collisions.
FAQ
Here are answers to the most common questions developers ask when building agentic workflows:
1. What is the difference between ReAct and Plan-and-Solve agent architectures?
ReAct is an iterative loop that alternates between reasoning and action on a step-by-step basis, making decisions dynamically without a long-term plan. Plan-and-Solve separates these phases: a planning model decomposes the goal into a list of sub-tasks, and an executor carries them out sequentially. Plan-and-Solve is generally faster and more cost-effective for multi-step tasks, while ReAct is better suited for highly unpredictable environments.
2. How does Directed Acyclic Graph (DAG) routing improve agent reliability?
DAG routing structures the execution flow along predefined paths with no loops. Because the execution paths are acyclic, the graph is mathematically guaranteed to terminate. This eliminates the risk of infinite loops and cost explosions, making the workflow predictable, easy to test, and highly auditable.
3. How do you prevent infinite loops in AI agent tool-calling?
You can prevent infinite loops by implementing a LoopGuard pattern in the state manager. This middleware monitors the frequency of tool calls during a session. If a tool is called with semantically similar parameters more than 3 times consecutively, the LoopGuard intercepts the loop and routes the workflow to a fallback node or manual escalation path.
4. What is the CLEAR framework for evaluating AI agents?
The CLEAR framework is a five-dimensional evaluation methodology used to assess agentic systems in production. It measures:
- Cost: The total token expenditure per task.
- Latency: The end-to-end response time.
- Efficiency: The token efficiency and routing overhead.
- Assurance: The accuracy of tool calls and structured outputs.
- Reliability: The rate of successful task completion without crashes.
5. How does LangGraph support cyclical agent workflows compared to standard DAG engines?
Standard workflow engines (like Apache Airflow or Prefect) are designed for DAGs and do not natively support loops or state-reverting transitions. LangGraph extends graph execution to support cyclical paths by modeling nodes as state transitions and edges as conditional routing logic, allowing agents to loop, self-correct, and maintain a shared state across turns.
6. When should I choose a simple LLM chain over a multi-agent graph?
Choose a simple LLM chain if the task is linear, predictable, and does not require conditional routing or tool-calling loops. If a process can be solved with a sequence of two or three fixed prompts, a graph architecture adds unnecessary latency, token cost, and debugging complexity.
7. What is "difficulty-aware routing" in LLM applications?
Difficulty-aware routing is an optimization pattern that uses a lightweight, low-cost classifier model to evaluate the complexity of an incoming query. Simple queries are routed to standard APIs or cheap, fast models, while complex, unstructured queries are routed to a multi-agent graph powered by frontier models. This balances cost and latency while preserving performance.
8. How does state contamination occur in multi-agent workflows?
State contamination occurs when multiple agents or nodes write to a shared global state without strict isolation or schemas. A node might overwrite or delete key-value pairs needed by other nodes, causing downstream logic to fail. It can be prevented by isolating state context and using explicit validation schemas for each node transition.
9. What infrastructure is required to deploy AI agents at scale in production?
Deploying agents at scale requires an asynchronous microservice layer (e.g., FastAPI), a persistent database for session state and checkpointing, a distributed task queue (like Temporal or Celery) to run workflows in background processes, an API gateway (such as LiteLLM) for load balancing and rate-limiting, and an observability tool (like Arize Phoenix or LangSmith) for tracing execution.
10. How does FlashAttention and context optimization impact agent workflows?
Agent workflows accumulate history quickly, leading to large context inputs. Large contexts cause model attention fragmentation and latency spikes. Technologies like FlashAttention speed up context processing, but developers must still manage context sizes. For a deep dive into mitigating attention issues, check out our guide on Attention Bottlenecks, FlashAttention, and GQA.
Key Takeaways
- Autonomy Requires Guardrails: Enterprise agents should not run with unconstrained tool access. Bound execution using structured graphs, conditional routing, and explicit termination conditions.
- Decouple Strategy from Action: Implement a Plan-and-Solve architecture for complex workflows to separate strategic planning (handled by expensive models) from task execution (handled by faster, cheaper models).
- Enforce Strict Input Validation: Enforce schemas at every node transition and tool call using tools like Pydantic or Zod. This prevents runtime errors and allows the agent to self-correct.
- Mitigate Infinite Loops Programmatically: Implement LoopGuard middleware to monitor tool-calling patterns, automatically breaking loops if the agent becomes stuck.
- Optimize Costs via Difficulty-Aware Routing: Use a lightweight classifier model to filter simple requests and reserve multi-agent graphs for complex queries.
- Always Use Run-Scoped Sessions: Isolate session checkpoints using run-scoped, globally unique identifiers (
session_id + uuid4()) to prevent state collisions in high-concurrency environments.
